1.词型还原与词干提取之间的区别与联系
词型还原:把任何形式的语言词汇还原成一般形式,还原后得到的那个词是具有一定意义的。
词干提取:把任何形式的语言词汇还原成它对应的词干或词根,但词干或词根本身不一定有意义。
联系:目前实现词型还原和词干提取的主流方法均是利用语言中存在的规则或者词典映射。
区别:
1)原理上:词干提取主要是采用 ‘缩减’ 的方法,将词所带的后缀去掉,而词型还原则是采用‘转换’的方法,将目标词转成其对应的最简单的形式,最一般的形式。
2)复杂性上:词干提取相对比较简单,词型还原则比较复杂,需要返回对应的原型,这涉及到后缀的转换和词性的识别,以区分相同词型但原型不同的词的区别。显然其中词性的识别的准确性直接影响着词型还原的准确性。
3)实现方法上:词干提取和词型还原的主流方法虽然相似,但其各有侧重。词干提取更侧重利用语言存在的规则去进行后缀的去除或缩减;而对于词型还原来说,仅仅依靠语言内在的规则来进行是远远不够的,它更偏向于利用词典中词型与原型的对应关系进行映射生成词典中的有效词。
4)返回结果上,词干提取的结果可能并不是完整的有意义的词,而词型还原一定是。
5)应用领域上, 词干提取和词型还原虽然均应用于信息检索和文本处理方面,但各有侧重。词干提取更多的是应用于信息检索方面,比如扩展检索,粒度更粗;而词型还原主要应用于文本挖掘,自然语言处理,粒度更细。
相对而言,词干提取是相对轻量级的词形归并方式,其结果为词干,并不一定具有实际意义,而词型还原比较复杂,返回的结果为词的原型,能承载一定的实际意义,具有很大的研究价值。
2. 词型还原
1). WordNet词型还原工具
>>> from nltk.stem import WordNetLemmatizer>>> wn_lem=WordNetLemmatizer()>>> wn_lem.lemmatize('lying')'lying'>>> wn_lem.lemmatize('worked')'worked'>>> wn_lem.lemmatize('worked', 'v')u'work' 但该方法有一个问题,就是它默认将词的不同时态为一个完整独立的词,而不加转换,只有明显的单复数才进行转换,并没有到达我们想要的归并相同词的效果。要达到我们的目标,必须指明词性,但词性判断的过程又是比较复杂的过程,所以总体上应用起来不是那麽方便。
2)TreeTagger
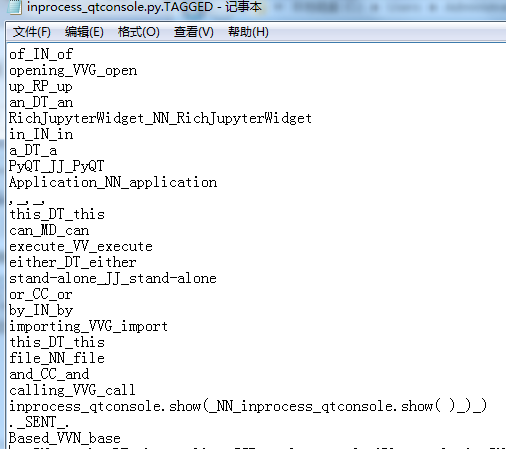
TreeTagger也是一个词汇处理工具,主要用于词性识别和词型还原。其返回结果分为三栏,左栏,中栏,右栏,分别对应目标词汇, 词性标注,原形。